· Daniel Suess · Technology · 14 min read
How World Models Enable Contextual Video Understanding
World models represent a shift from pattern recognition to causal simulation, enabling AI to understand narrative structure and temporal relationships, not just detect objects.
A state-of-the-art computer vision model can identify 10,000 objects in a single frame with 95% accuracy. But it can’t tell you why a character’s subtle facial expression in minute 40 matters because of a scene that happened in minute 3.
That requires something fundamentally different: a world model.
World models shift from isolated frame analysis to understanding temporal causality and narrative structure across long-form video.
When Pattern Recognition Isn’t Enough
Traditional computer vision excels at spatial recognition: object detection, segmentation, classification. These are solved problems for individual frames. A modern vision transformer can recognize a glass on a table, identify the brand of the glass, estimate its volume, and detect condensation on the surface. Impressive, but limited.
It can’t predict that when someone’s hand approaches the glass, they’ll grasp it and lift it to their mouth. It can’t anticipate that if the glass is knocked off the table, it will fall and shatter. It can’t understand why that specific glass matters to the story when it was introduced as a prop 40 minutes earlier.
Frame-by-frame computer vision processes each image independently. There’s no memory of what came before, no expectation of what comes next, and no understanding of why events happen. For many applications (inventory counting, object tracking, basic scene classification), this is sufficient.
But for anything requiring genuine comprehension of video content, frame-level recognition hits a wall. Understanding narrative requires causal reasoning, temporal coherence, and contextual awareness that spans minutes or hours, not milliseconds between frames.
Consider Chekhov’s gun: if a gun appears in Act 1, it must fire by Act 3. A frame-by-frame system sees the gun in both scenes but has no concept of the narrative connection. It doesn’t know the first appearance is a setup, the second is payoff, and the 40 minutes between them create dramatic tension.
This is the gap world models address.
See world model-powered video understanding in action: Try Visonic AI’s demo to experience how AI comprehends long-form narrative, not just objects in frames.
From Recognition to Simulation
A world model is an AI system’s internal simulation of how the world works. Rather than simply matching patterns in pixels, a world model builds representations of physical laws, social dynamics, causal relationships, and temporal dependencies. It predicts future states from current observations.
The paradigm shift looks like this:
| Frame-by-Frame Computer Vision | World Model |
|---|---|
| ”What is visible in this frame?" | "What will happen next?” |
| Pattern matching in pixels | Simulation of world dynamics |
| Independent frame processing | Temporal coherence across frames |
| No causal understanding | Causal reasoning and prediction |
| Spatial only | Spatial + temporal + causal |
Google DeepMind’s Genie 3, released in 2025, demonstrates this shift concretely. Unlike video generation models that produce fixed sequences, Genie 3 creates interactive environments you can navigate in real time at 24 frames per second. The system “teaches itself how the world works, how objects move, fall, and interact, by remembering what it has generated rather than relying on a hard-coded physics engine” (DeepMind, 2025).
The model learned gravity. It learned that doors open on hinges. It learned spatial perspective. None of this was programmed explicitly. It emerged from predicting what comes next in video sequences.
Similarly, DreamerV3, published in Nature in 2025, “learns a model of the environment and improves its behaviour by imagining future scenarios” (Hafner et al., 2025). The system doesn’t just recognize states - it simulates possible futures and reasons about which actions lead to desired outcomes.
OpenAI’s SORA was explicitly framed as a “world simulator” rather than merely a video generator. The technical report states SORA is “trained to generate videos of realistic or imaginative scenes and show potential in simulating the physical world.”
The pattern is clear: leading AI research organizations are shifting from frame-level recognition to world-level simulation.
Three Paths to World Modeling
Multiple technical approaches to world modeling have emerged, differing in how they represent and compute predictions. Understanding these architectures clarifies what “world model” actually means technically.
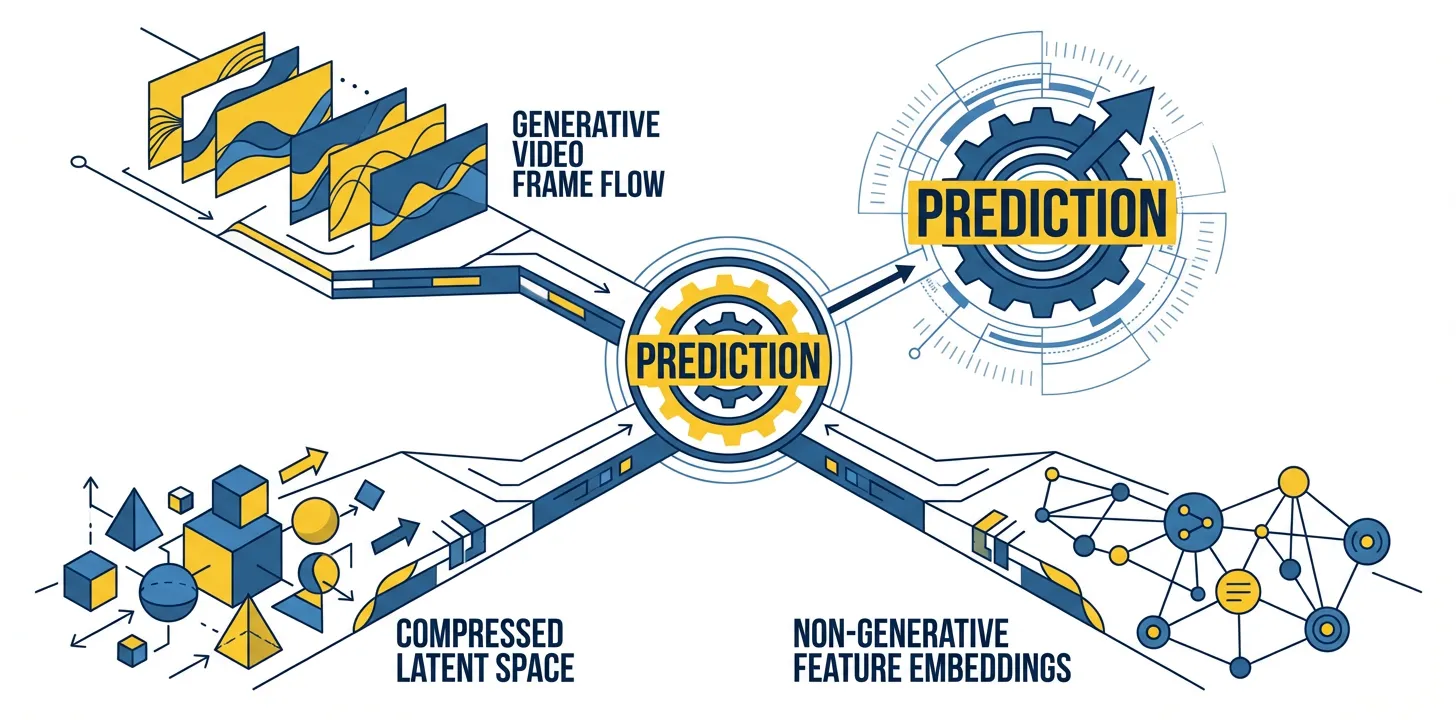 Three distinct paths to world modeling (generative, latent, and non-generative) all converge on predictive learning as the core mechanism.
Three distinct paths to world modeling (generative, latent, and non-generative) all converge on predictive learning as the core mechanism.
Generative World Models
Generative approaches (SORA, Genie, Runway) learn world dynamics through video generation. The model is trained to predict future frames given past frames. To generate believable video, it must implicitly learn physics, perspective, object permanence, and causality.
SORA uses a diffusion transformer architecture with patch-based representations, allowing it to generate videos up to one minute long at variable resolutions (OpenAI, 2024). The patches are spacetime units, encoding both spatial and temporal dimensions, forcing the model to represent temporal relationships, not just spatial patterns.
The technical insight: by decomposing video into spacetime patches rather than treating each frame independently, the architecture inherently captures motion and change. A falling object isn’t represented as disconnected still frames - it’s a continuous trajectory through spacetime.
Genie 3 achieves real-time performance: 720p resolution at 24 frames per second, maintaining physical consistency for several minutes (DeepMind, 2025). That temporal consistency is the key differentiator. The model remembers what it previously generated and maintains coherent physics across time.
The computational cost is substantial. Diffusion models require many denoising steps, but the fidelity is highest among current approaches.
Latent World Models
Latent approaches (DreamerV3, REM) encode observations into compact latent representations and perform prediction in this lower-dimensional space rather than pixel space. This is far more computationally efficient while retaining the core capability: simulating future states.
DreamerV3 encodes sensory inputs into categorical representations and predicts future representations and rewards given actions (Hafner et al., 2025). The world model operates entirely in latent space. When a decision needs to be made, the model “imagines” rollouts (simulated futures) in this compressed representation.
This approach enabled DreamerV3 to master over 150 diverse tasks with a single configuration, including becoming the first reinforcement learning algorithm to collect diamonds in Minecraft from scratch without human data or curriculum learning. The latent world model learned complex causal chains (find wood → craft tools → mine stone → smelt iron → create better tools → mine deeper → find diamonds) entirely through prediction.
The efficiency gain is substantial. Predicting in a learned latent space with dimensions in the hundreds versus predicting raw pixels (millions of dimensions per frame) reduces computation by orders of magnitude while preserving the information needed for decision-making.
For control and decision-making applications, latent world models offer the best efficiency-to-performance ratio currently available.
Non-Generative Representations
Yann LeCun’s Joint Embedding Predictive Architecture (JEPA) takes a different path: learn representations without generating pixels at all. JEPA predicts in an abstract feature space, focusing on what’s predictable and ignoring irrelevant details that can’t be anticipated.
LeCun, a Turing Award winner who recently left Meta to launch Advanced Machine Intelligence (AMI) Labs with a €3 billion valuation, argues that large language models are “an off ramp on the road to human-level AI” and that world models represent the correct path forward (MIT Technology Review, 2026).
His bet: learning abstract representations that capture world dynamics is more efficient than generating detailed predictions. “Learn an abstract representation of the world and make predictions in that abstract space, ignoring the details you can’t predict.”
The philosophical difference matters. Generative models try to predict everything, including inherently unpredictable details like exact leaf textures on a tree swaying in wind. JEPA says: predict the motion pattern (wind direction, swaying frequency) but don’t waste compute on unpredictable microdetails. Focus on the abstractions that matter for understanding.
Time will tell which approach proves most effective, but the convergence on prediction as the core mechanism is significant. All three paths (generative, latent, non-generative) learn by anticipating what comes next, not by matching patterns in static images.
From Lab to Production
World models have transitioned from academic research to commercial deployment with remarkable speed. The field was formalized with a comprehensive survey published in ACM Computing Surveys in 2025, “Understanding World or Predicting Future? A Comprehensive Survey of World Models”, establishing the theoretical foundation.
Simultaneously, practical demonstrations validated the approach:
Academic validation: DreamerV3’s publication in Nature (not a machine learning conference, but the premier interdisciplinary science journal) signals the approach has moved beyond niche research to fundamental scientific contribution.
Industry momentum: Yann LeCun, one of the three researchers who shared the 2018 Turing Award for deep learning, left his position as Meta’s Chief AI Scientist to launch AMI Labs focused exclusively on world models. The startup is reportedly seeking €500 million at a €3 billion valuation before product launch (TechCrunch, 2025).
Commercial deployment: Google DeepMind made Genie 3 available to Google AI Ultra subscribers, marking the first time a general-purpose world model has been deployed to paying users.
This trajectory, from research to Nature publication to commercial deployment in under two years, is extraordinarily fast for fundamental AI architecture shifts. Compare this to transformers, which took roughly five years from “Attention Is All You Need” (2017) to widespread commercial deployment. World models are accelerating faster.
Capabilities Beyond Recognition
What do world models enable that frame-by-frame computer vision cannot? Four critical capabilities matter for video understanding applications.
1. Prediction and Anticipation
World models predict future states. When a character reaches for a glass, the model anticipates the hand will grasp it. When someone approaches a door, the model expects it will open. This sounds trivial, but it’s the foundation for understanding partial observations.
If a hand enters the frame reaching toward something off-screen, a world model can infer what’s happening based on posture, motion trajectory, and context. A frame-level system sees only “hand moving right” - no anticipation, no inference about the unseen.
This matters critically during scene cuts, fast edits, or occluded views. The model maintains continuity by predicting what should happen, filling gaps that frame-level vision cannot address.
In practice, this means a world model can maintain object permanence: if a character places a key on a table in scene 1, then the camera cuts away, the model predicts the key remains there until someone moves it. Frame-by-frame vision has no memory of the key once it leaves the frame.
2. Causal Reasoning
Understanding why events occur, not just what happens, requires causal models. If a glass is knocked off a table, a world model predicts it will fall (gravity) and shatter (fragility). These aren’t visual patterns - they’re physical laws the model has internalized.
Recent research on “Causality Matters: How Temporal Information Emerges in Video Language Models” demonstrates that “temporal reasoning emerges from inter-visual token interactions under the constraints of causal attention, which implicitly encodes temporal structure.”
Causal reasoning enables anomaly detection: when something violates expected physics or social norms, the model recognizes it as significant. A character acting against their established behavioral pattern becomes salient precisely because it violates the model’s predictions.
This is how world models can identify narratively important moments. A gun appearing on a table isn’t inherently significant, but if characters have been unarmed for 40 minutes, and now a gun appears in a tense scene, the model flags this as violating expected state and therefore noteworthy.
3. Temporal Coherence Across Long Videos
Maintaining consistency over minutes or hours remains a frontier challenge. As research on long-form video understanding notes, “constrained context windows fragment temporal and semantic coherence” in current systems.
Genie 3’s temporal consistency spans “several minutes,” impressive, but still far short of a 90-minute film. TemporalVLM addresses this by dividing videos into short-term clips encoded with timestamps, fusing across overlapping temporal windows, and using BiLSTM modules for global feature aggregation.
The architecture challenge is clear: how do we maintain world model coherence across the timescales that matter for narrative content? Current approaches use hierarchical processing (local consistency within clips, global coherence across clips), but this remains an active research area.
The compute-memory tradeoff is fundamental. To predict accurately, the model needs context. To process hours of video, context must be compressed. Compression loses information. The question is: which information can we safely discard and which must be retained for long-range coherence?
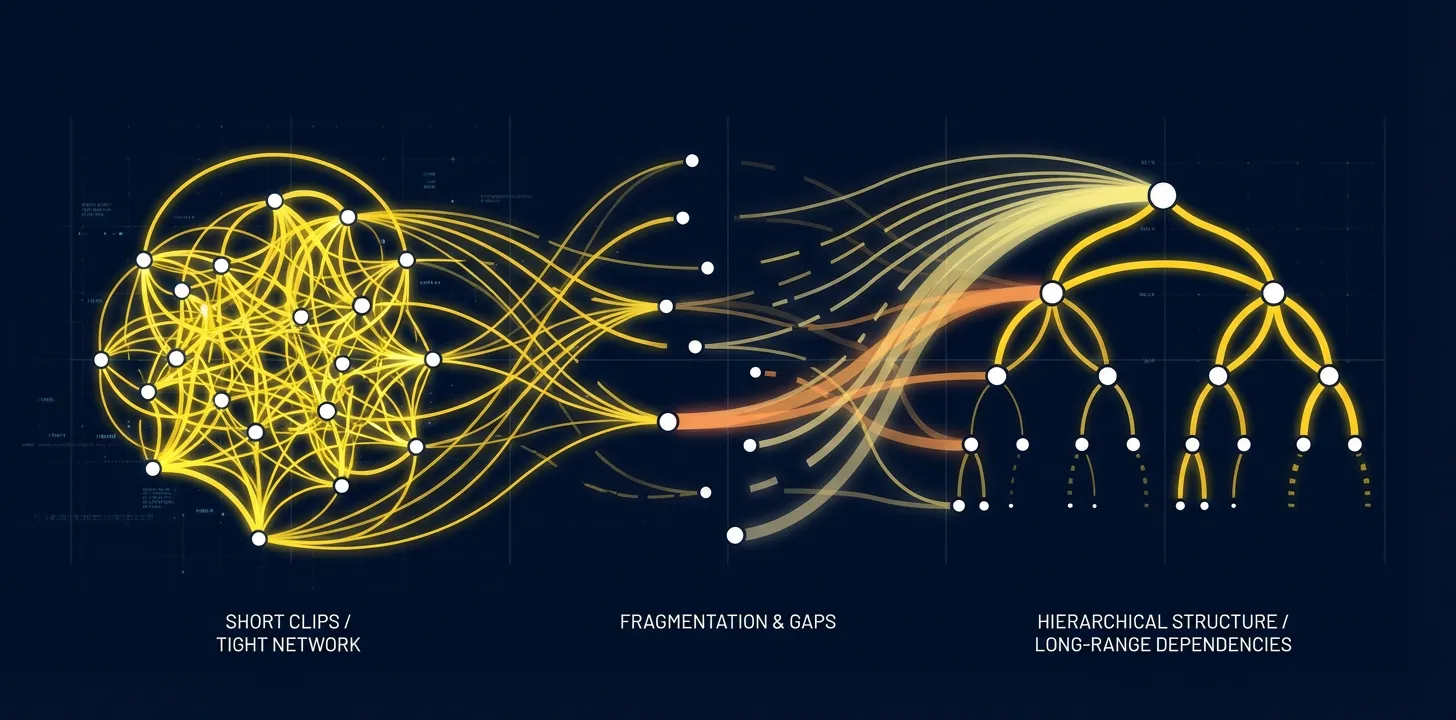 Maintaining world model coherence across feature-film timescales remains an active research challenge, requiring hierarchical processing strategies.
Maintaining world model coherence across feature-film timescales remains an active research challenge, requiring hierarchical processing strategies.
4. Contextual Disambiguation
The same visual can mean entirely different things depending on context. A character running:
- In an action film: fleeing danger
- In a romantic comedy: rushing to catch a departing love interest
- In a sports documentary: competing in a race
Frame-level vision sees “person running.” A world model incorporates genre conventions, narrative structure, character history, and scene context to determine what the action means.
This contextual understanding is essential for any application requiring interpretation, not just classification. The pixels are identical (a person’s legs moving rapidly), but the semantic meaning differs entirely based on the world model’s accumulated understanding of genre, character state, and narrative position.
From Object Detection to Narrative Understanding
Audio description exposes the gap between recognition and comprehension with unusual clarity. The task isn’t merely describing visible elements - it’s conveying narrative significance.
Consider two descriptions of the same visual:
Frame-level: “A woman looks at a man.”
World-model-informed: “Sarah’s expression reveals she recognizes the man from the photograph.”
The second description requires understanding:
- Who Sarah is (character tracking across 90 minutes)
- What photograph was shown earlier (temporal memory spanning tens of minutes)
- That recognition is narratively significant (story structure understanding)
- How facial expressions convey internal states (learned social dynamics)
Frame-by-frame computer vision provides the first description. World models enable moving toward the second.
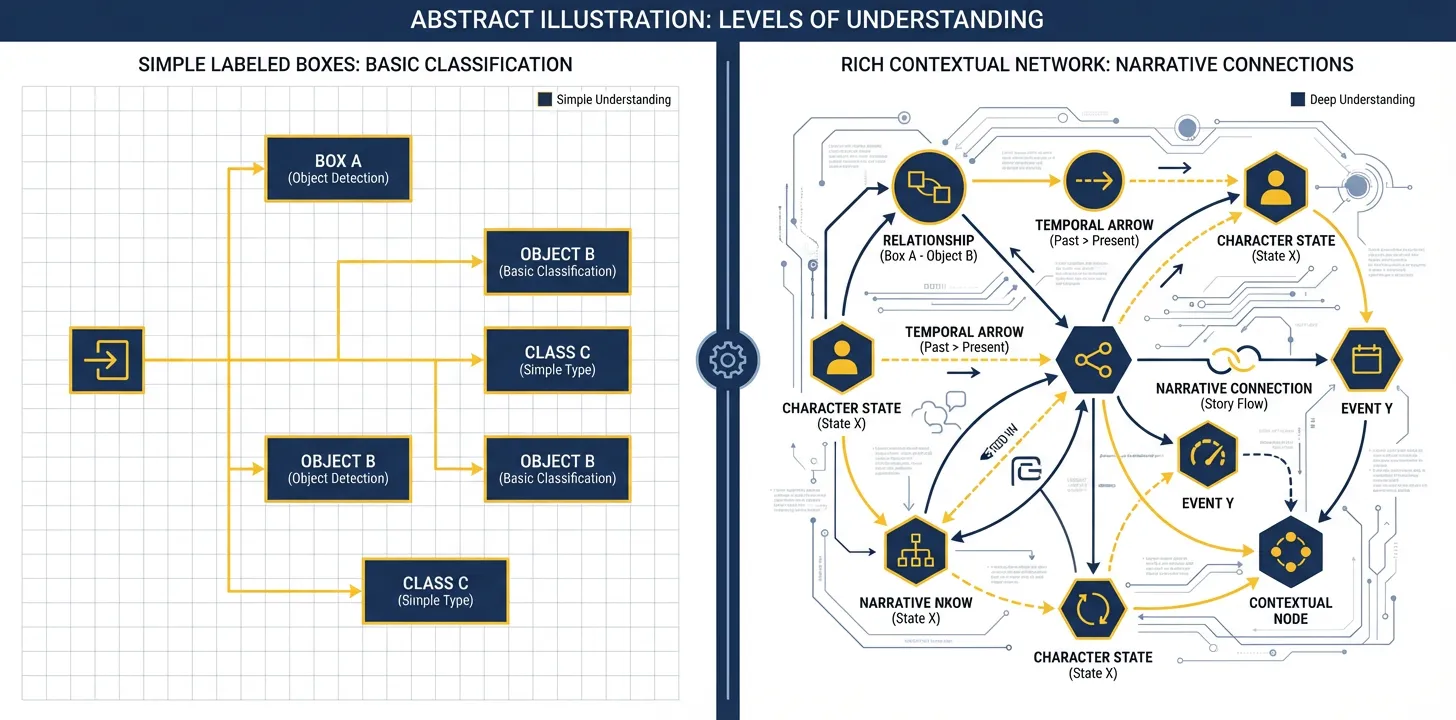 The difference between object detection and narrative understanding: world models enable contextually aware descriptions that convey story significance.
The difference between object detection and narrative understanding: world models enable contextually aware descriptions that convey story significance.
Experience the difference: Get started with Visonic AI to see how world model-powered understanding creates broadcast-quality audio descriptions that capture narrative context, not just visible objects.
At Visonic AI, our focus on long-form video understanding means tackling exactly these challenges. Audio description for a 90-minute film requires:
- Predicting narrative trajectories to distinguish setups from background details
- Understanding character states that evolve across the entire runtime
- Recognizing genre conventions that inform description priorities
- Maintaining coherence and consistency throughout
This goes beyond what current video generation models (which excel at physics simulation) or reinforcement learning agents (optimized for control tasks) are designed for. It requires world models plus narrative comprehension: understanding dramatic structure, character psychology, thematic elements.
The systems that matter aren’t those with the most impressive physics simulation or the highest-resolution generation. They’re the ones that combine world model foundations with story-specific reasoning.
The State of the Art in 2026
World models are advancing rapidly, but they’re not magic. Understanding current capabilities and honest limitations is critical for evaluating their applicability.
What works today:
Real-time generation is achievable: Genie 3 demonstrates 720p at 24 frames per second with interactive control. Physical consistency is learned: models discover gravity, object permanence, and basic mechanics without explicit programming. Temporal coherence spans several minutes with current architectures. Novel scenario generation allows exploring situations not present in training data.
Current limitations:
Computational cost is substantial. Real-time performance requires significant GPU resources, practical for research and premium applications, but not yet commodity-level compute. Running Genie 3 at 24fps requires hardware most content creators don’t have.
Temporal scope remains bounded. Minutes, not hours. Maintaining world model coherence across feature-film length is an unsolved problem. Current approaches use hierarchical strategies, but long-range dependencies are challenging.
Narrative ambiguity requires human judgment. Physics is objective: gravity always pulls objects down. Story interpretation isn’t. Whether a character’s expression conveys “subtle concern” or “mild annoyance” can be contextually ambiguous. World models handle physical prediction better than interpretive nuance.
Training data biases affect performance. A model trained primarily on action films will have different priors than one trained on documentaries. Genre, cultural context, and visual style all influence learned world dynamics.
Failure modes under distribution shift: when presented with visual patterns far from training data, models can hallucinate physics violations or lose temporal coherence. A world model trained on realistic video may fail on animated content with different physics, or stylized cinematography with unconventional editing.
The honest assessment: world models excel at physical prediction and temporal consistency. Narrative comprehension (understanding dramatic structure, character psychology, thematic elements) requires additional capabilities beyond current world modeling techniques.
From Frames to Worlds
The difference between recognizing objects in a frame and understanding a narrative is the difference between a camera and a mind. World models bridge that gap, not completely, but fundamentally.
When Yann LeCun stakes a €3 billion startup on this approach, when Google DeepMind deploys interactive world models to subscribers, when Nature publishes world model research, the signal is clear. This isn’t speculative future technology. It’s happening now.
For video AI applications requiring genuine understanding rather than pattern matching, world models are becoming table stakes. The question isn’t whether to adopt world modeling approaches, but which technical path (generative, latent, or non-generative) best fits your application’s requirements and constraints.
Experience World Model-Powered Video Understanding
At Visonic AI, our approach to audio description is built on these foundations, extended with narrative-specific reasoning for long-form content.
Ready to see it in action?
- Explore our products: See what’s available - AI audio description, auto-summarization, and auto-shorts
- Get started with Visonic AI: Sign in to upload your video and experience AI that understands narrative context, not just objects
- Contact our team: Discuss how world model-powered video AI can transform your content workflow
Further reading:



